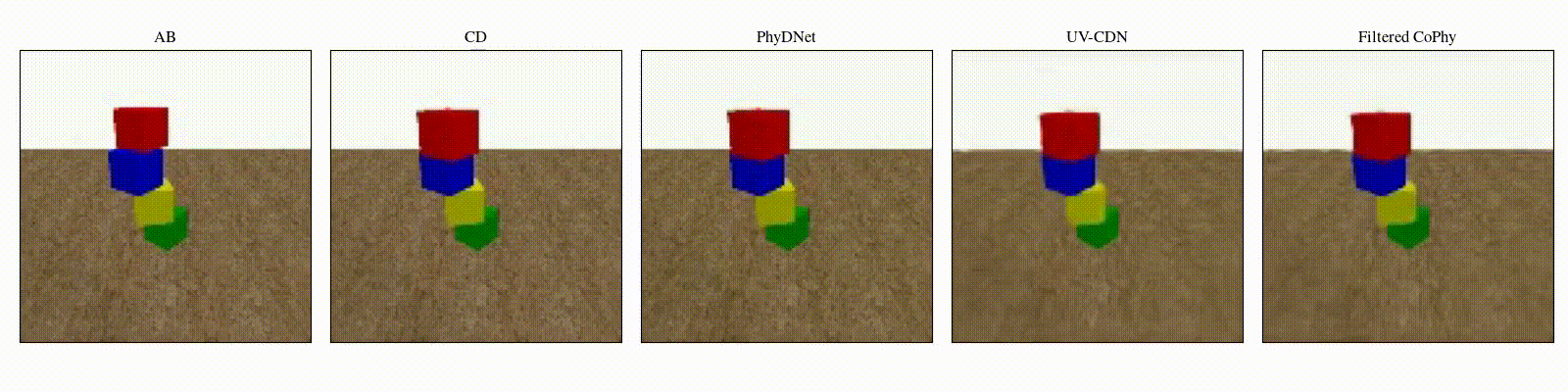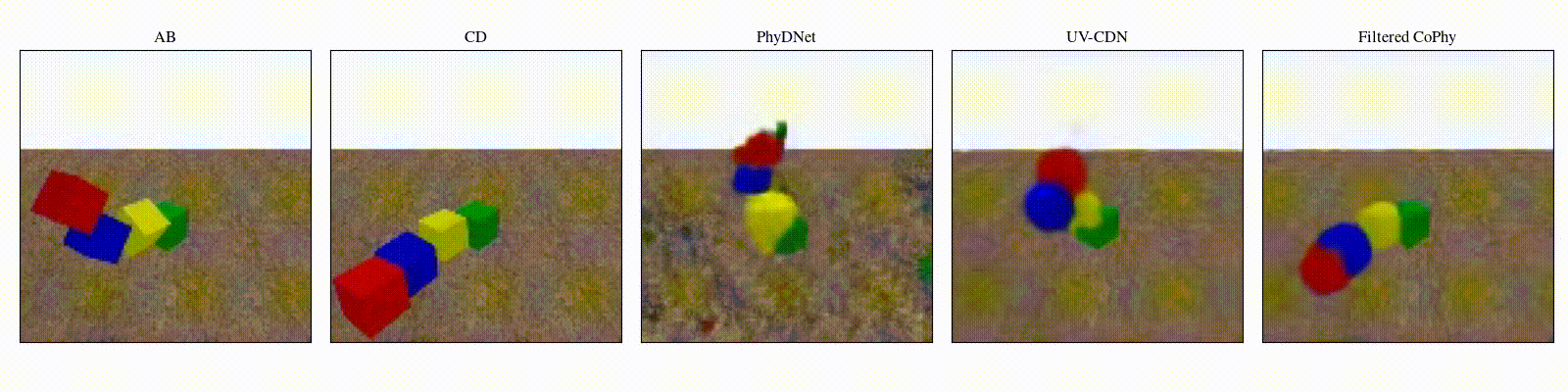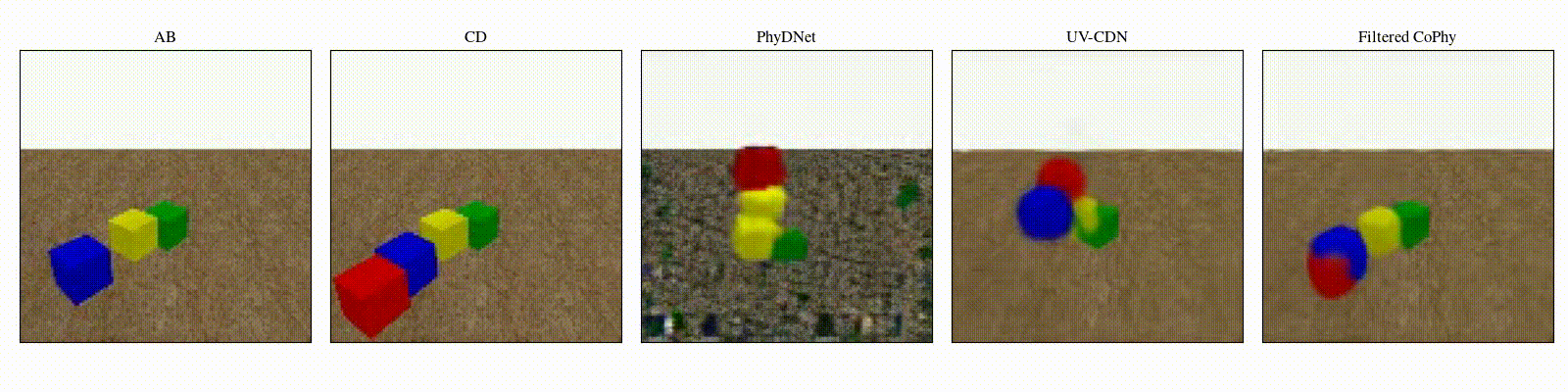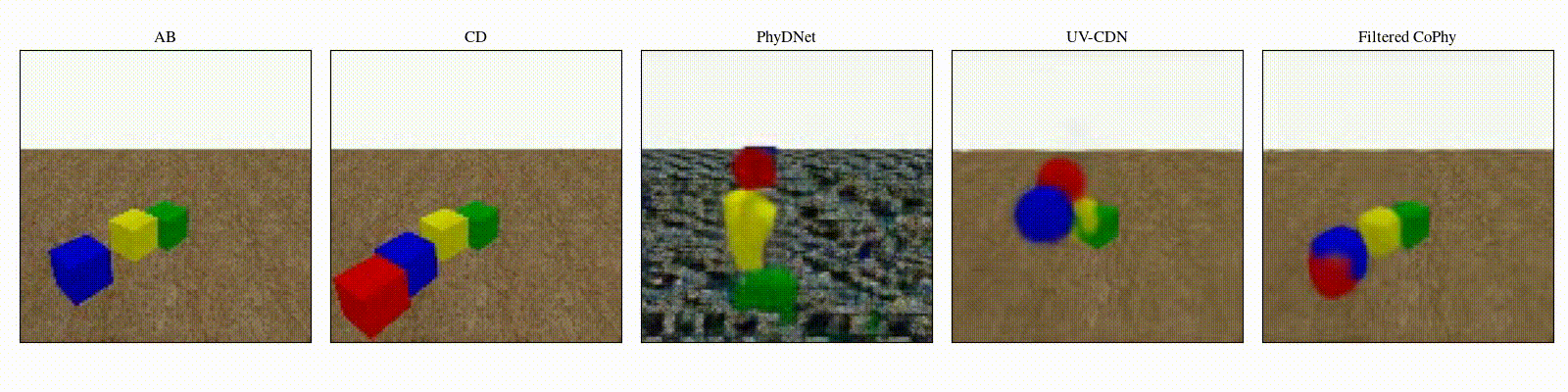
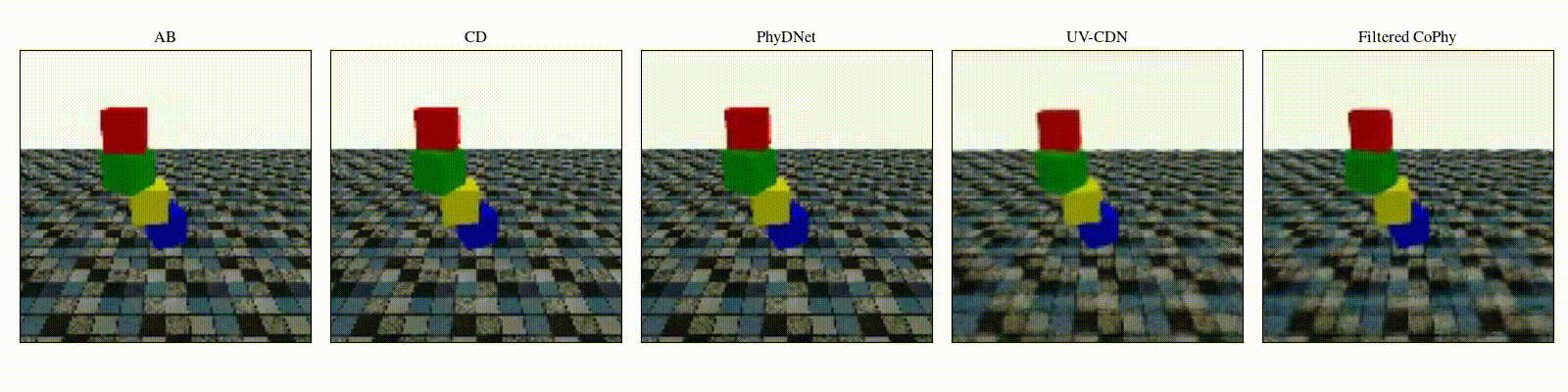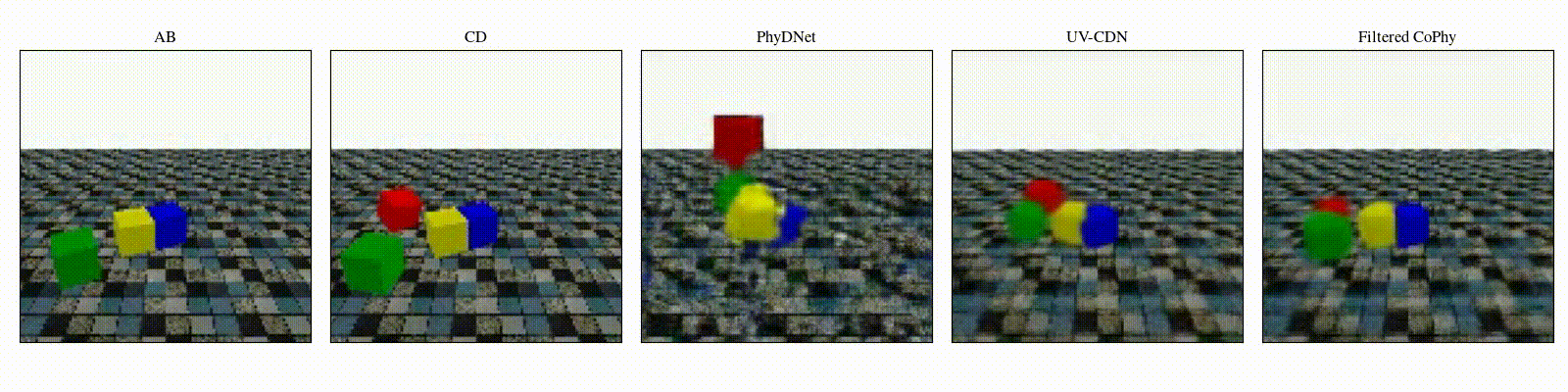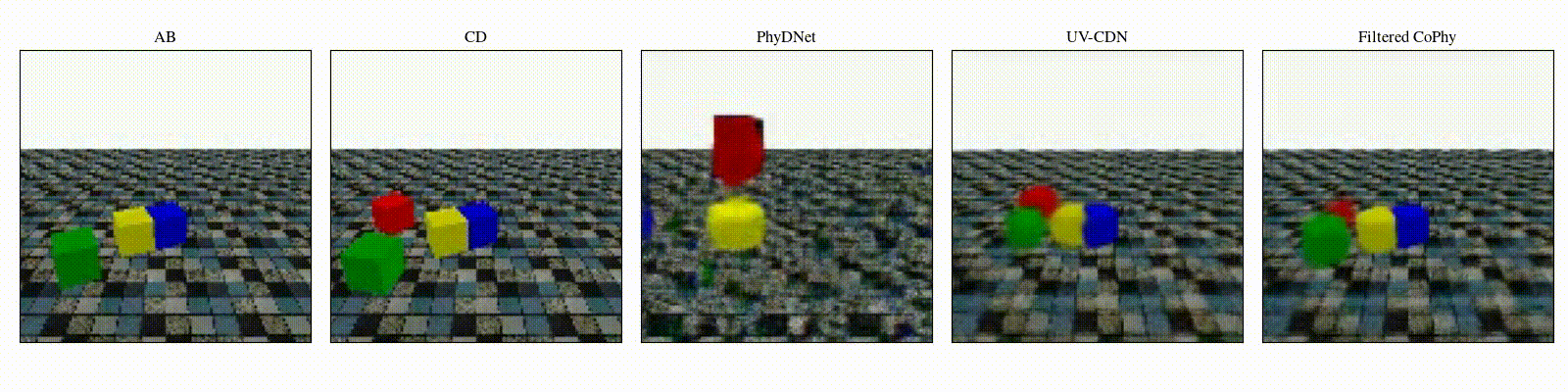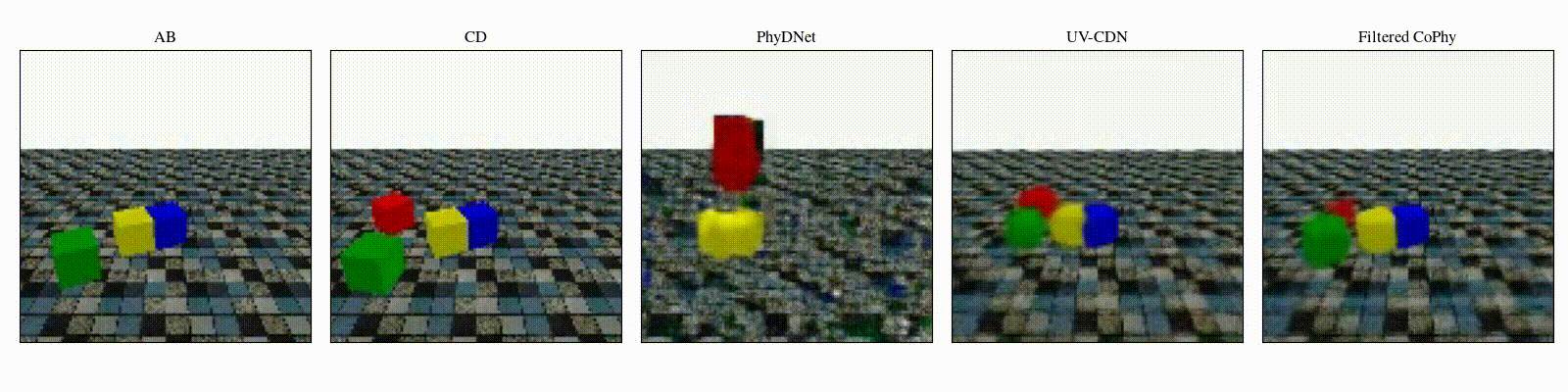
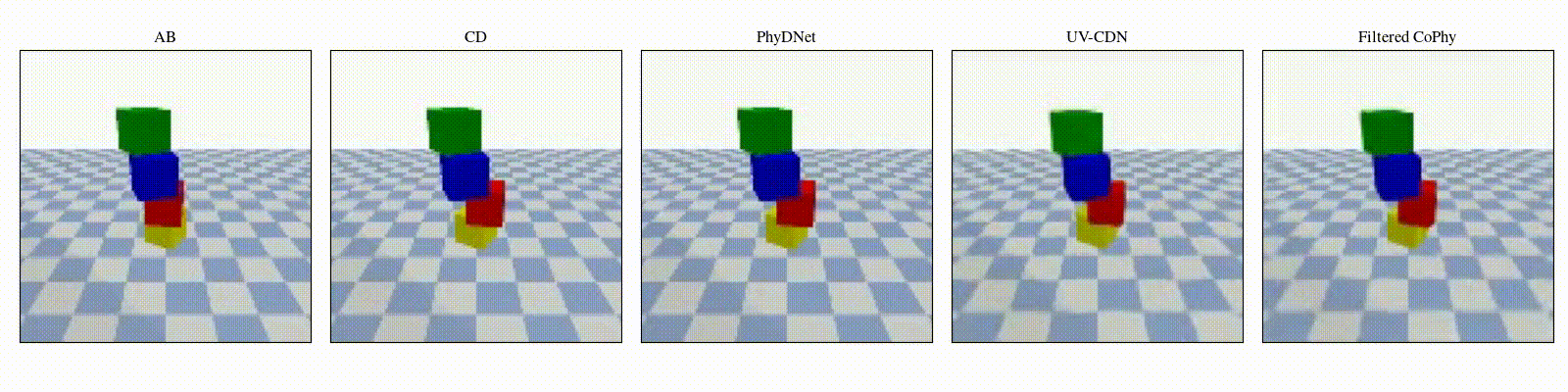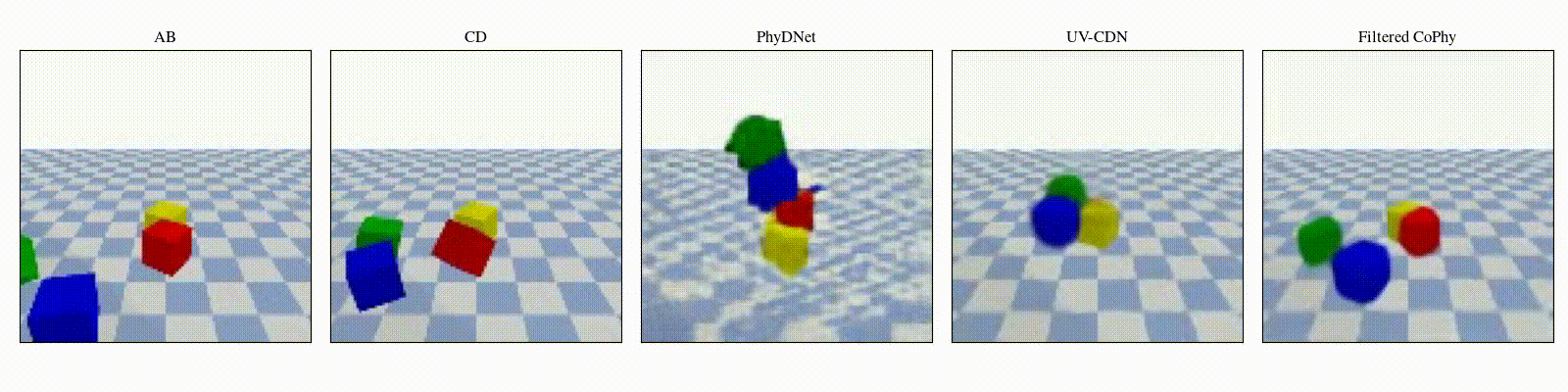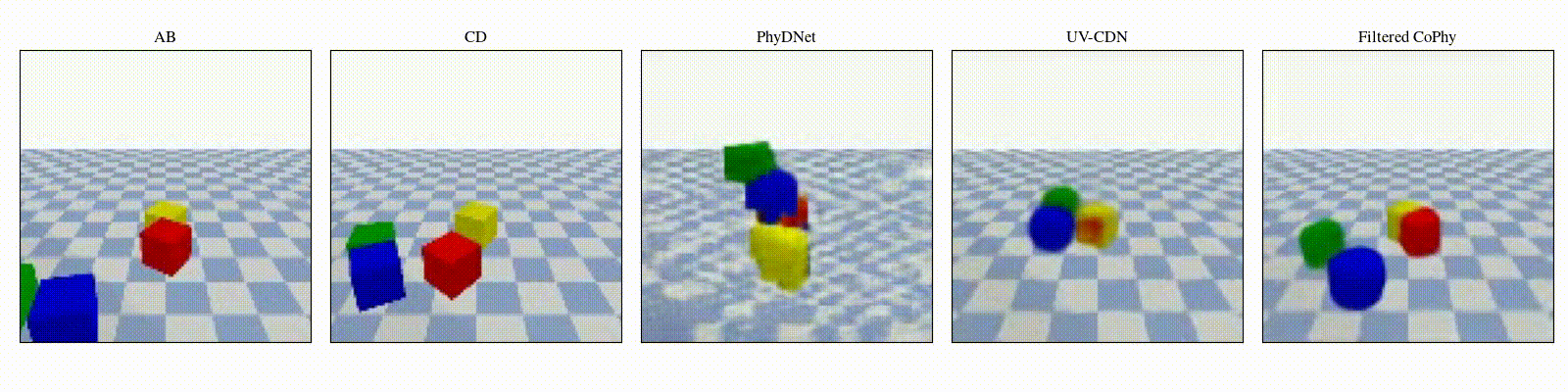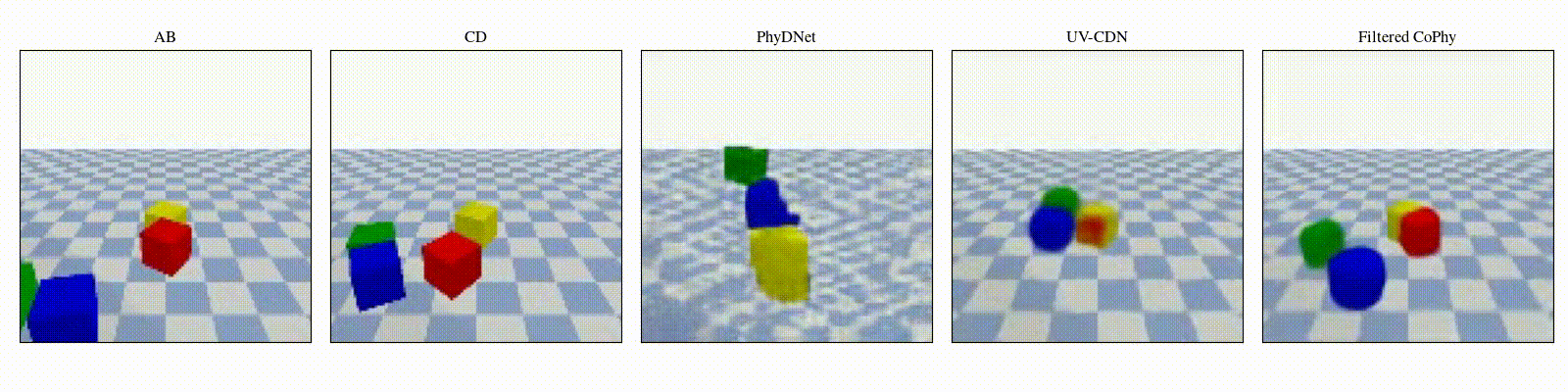
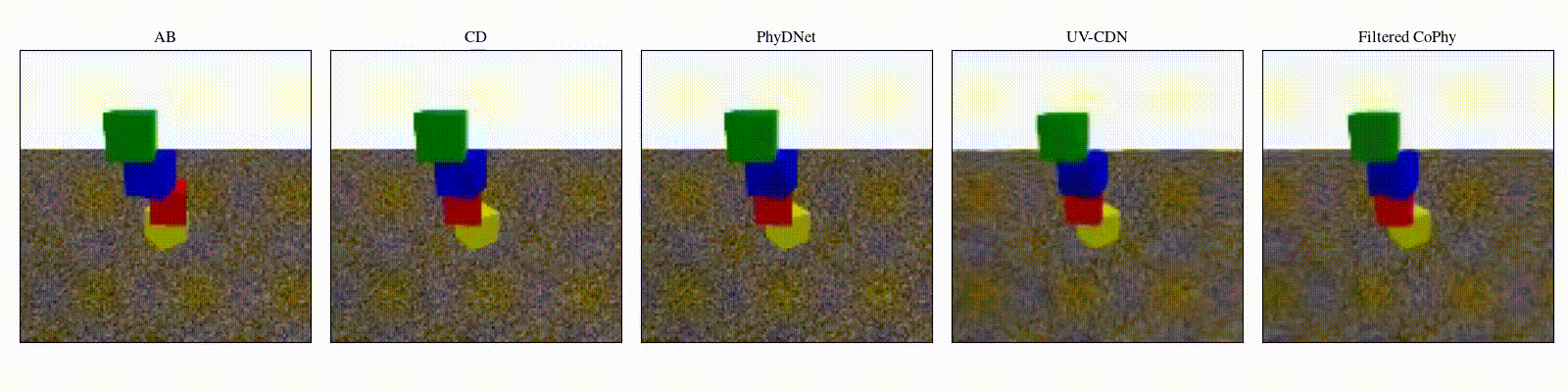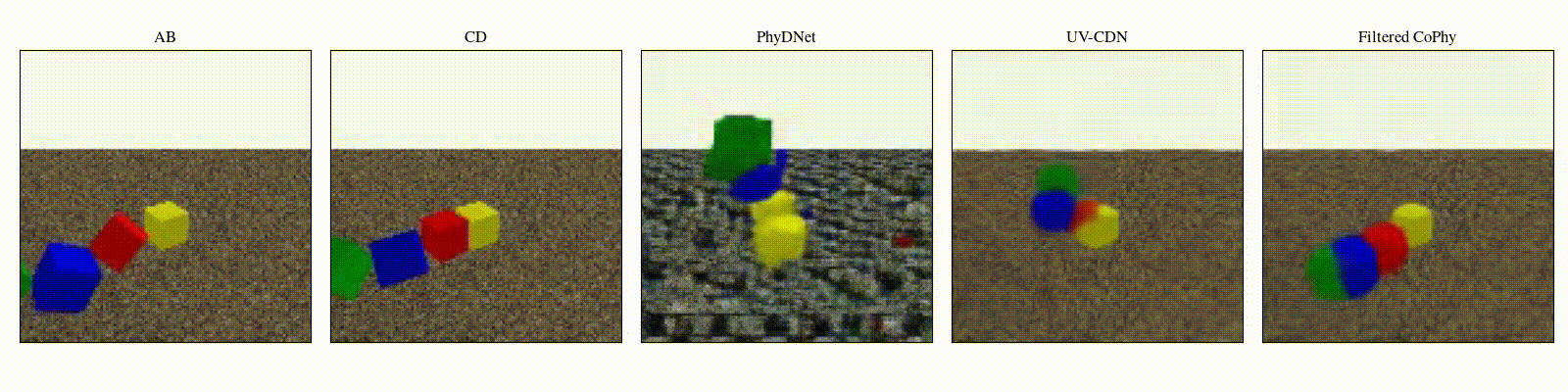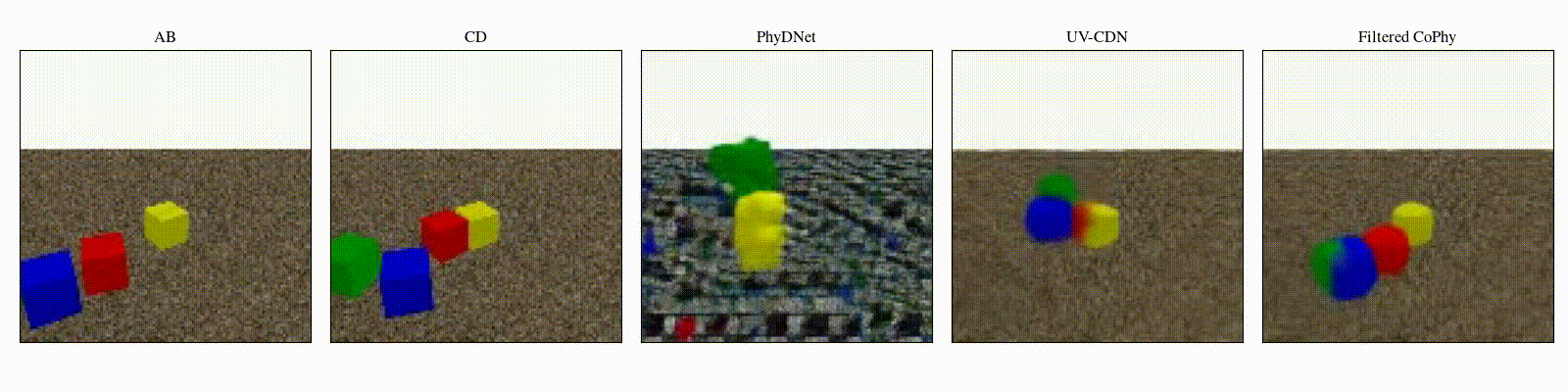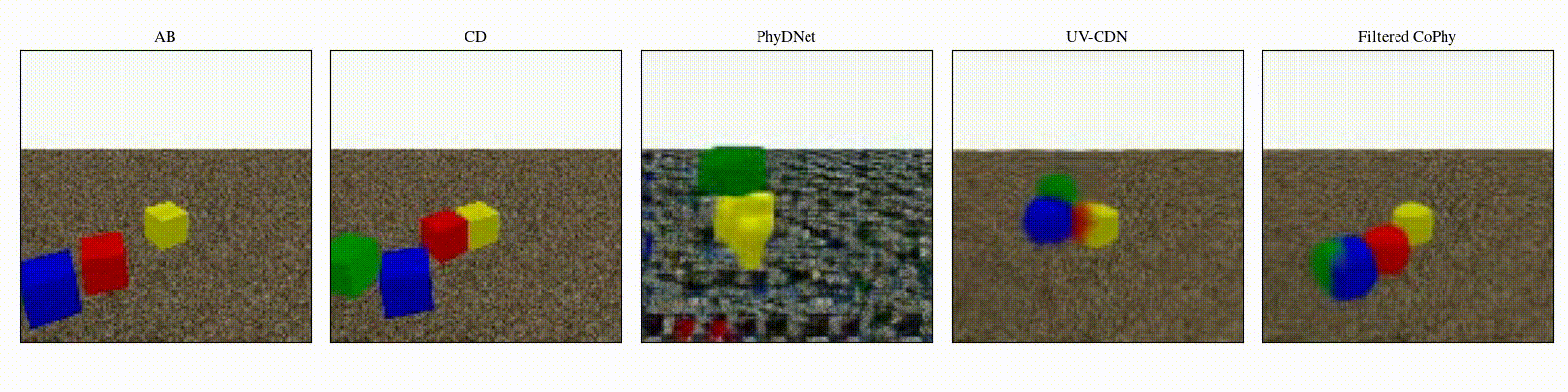
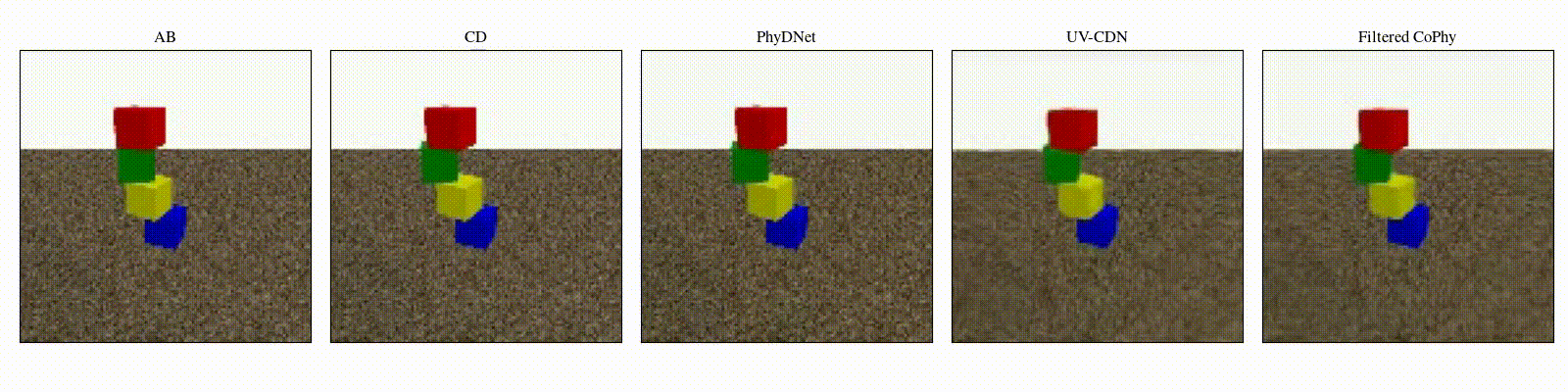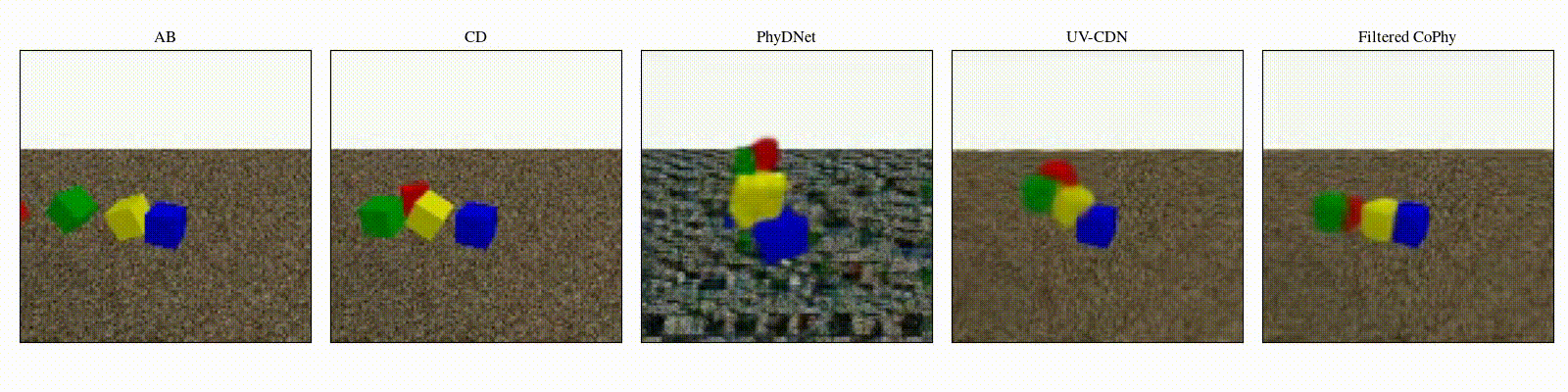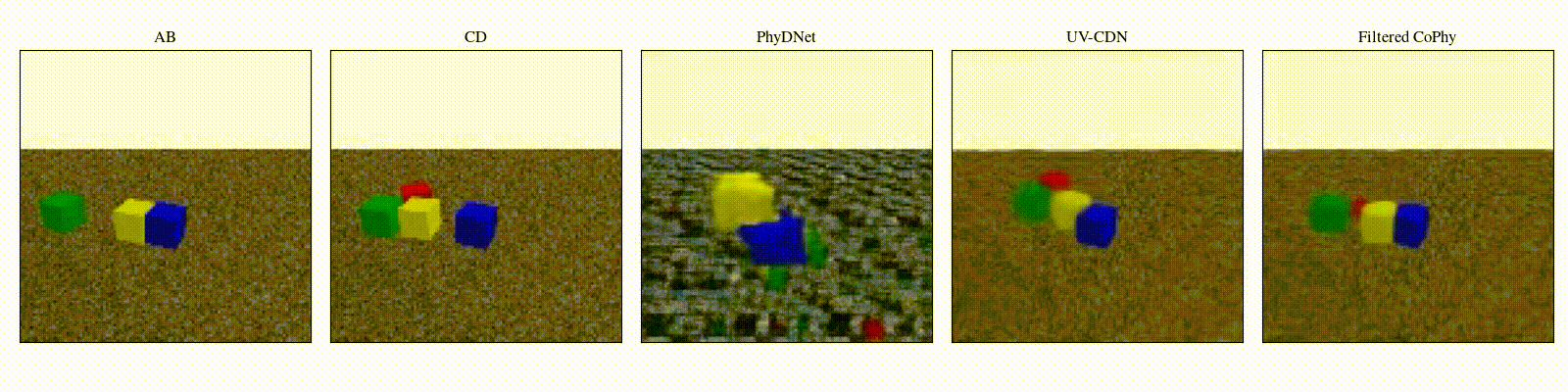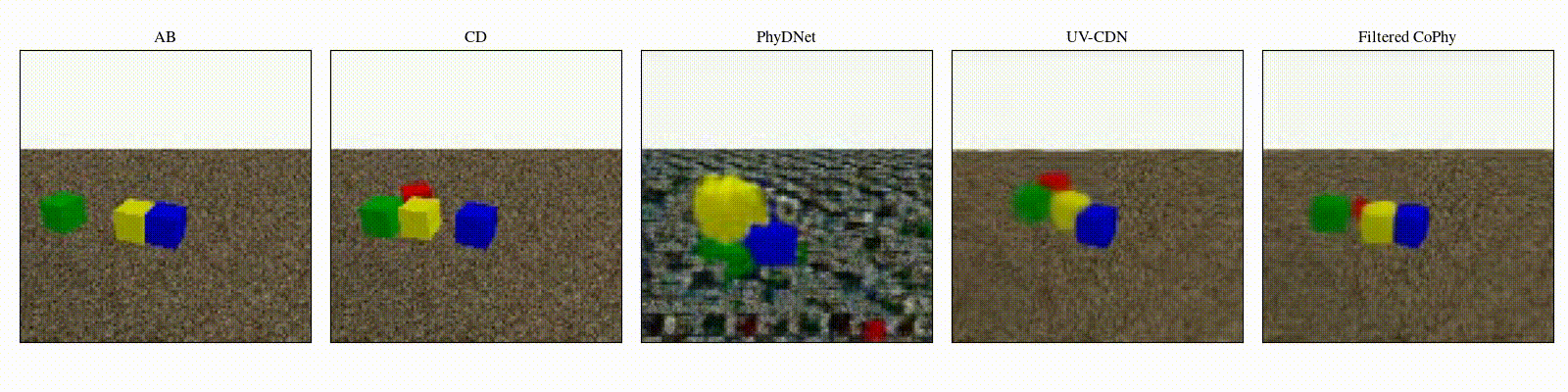
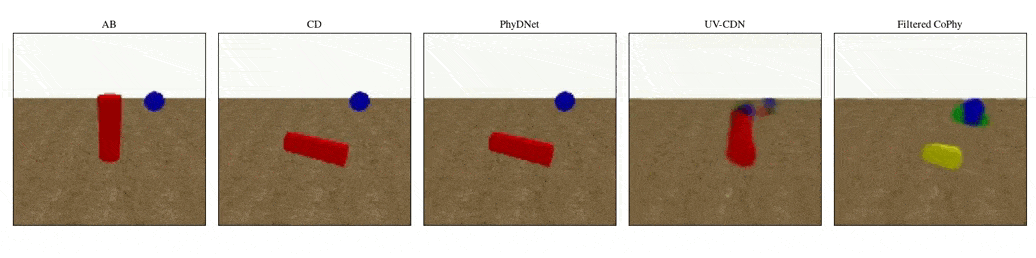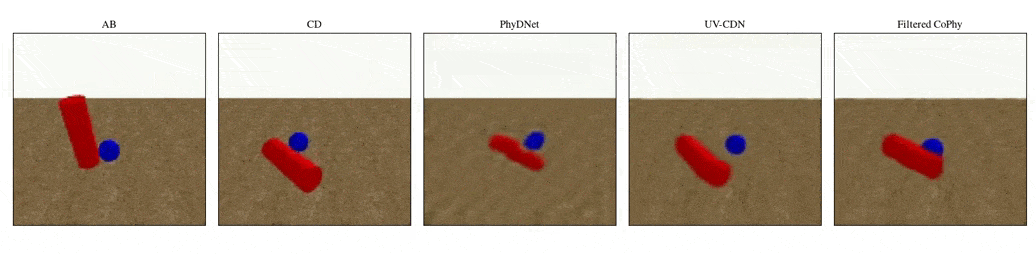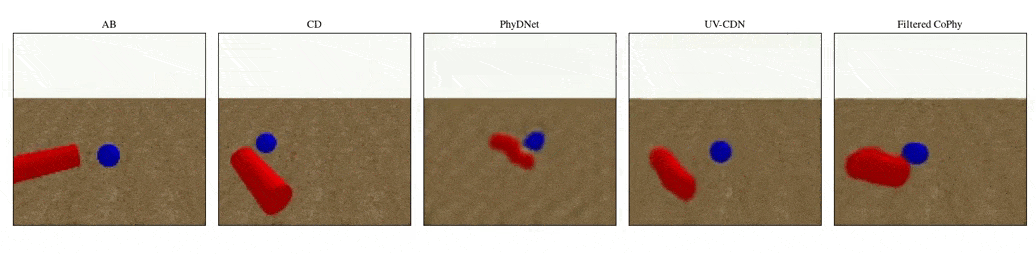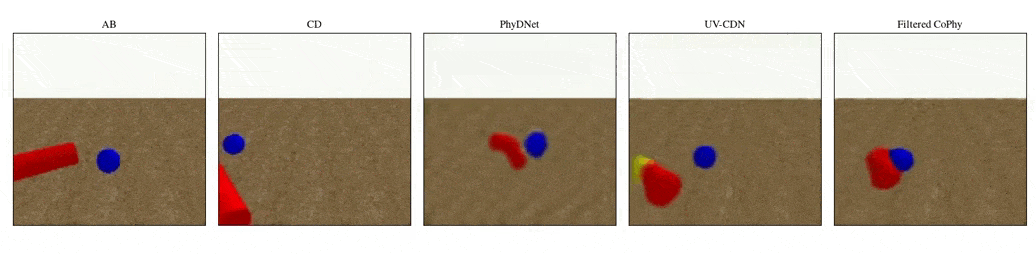
We introduce
Filtered-CoPhy, a counterfactual physics benchmark suite for counterfactual reasoning in
pixel space. Building on the work of
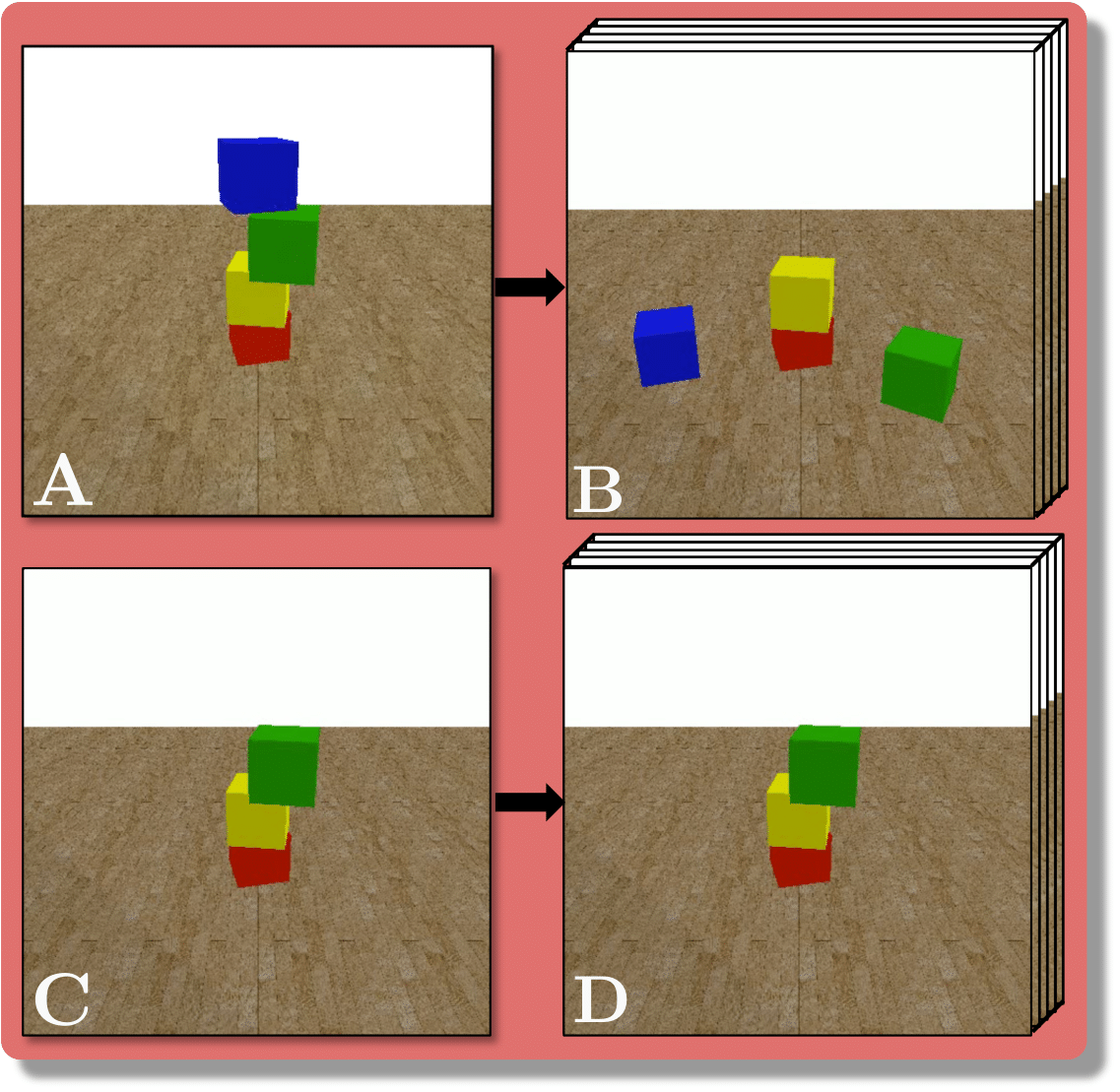
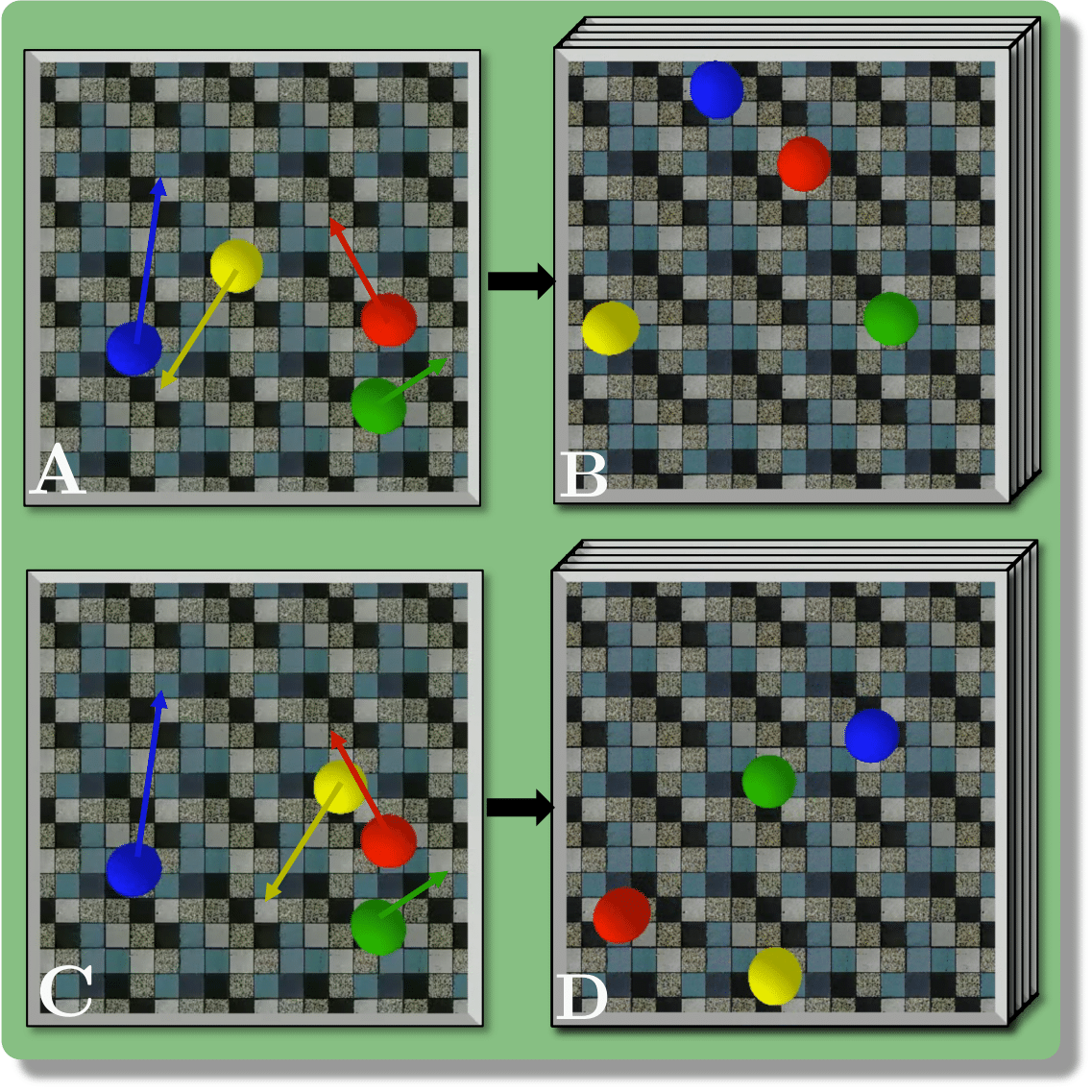
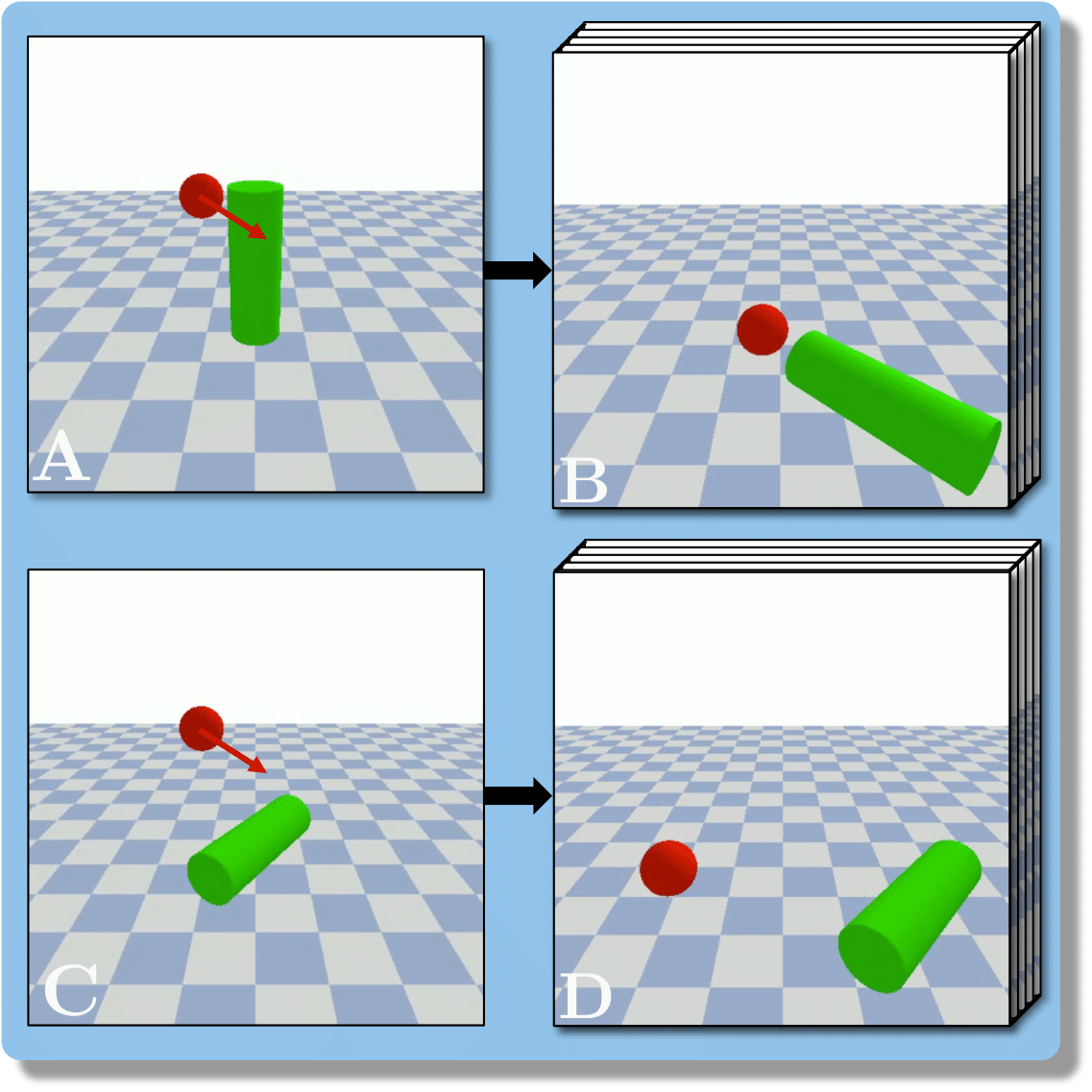
Baradel & al. (2019), our benchmark is composed of three scenarios : BlocktowerCF, BallsCF and CollisionCF.
The benchmark has been carefully designed and generated imposing constraints on identifiability and
counterfactuality. Each scenario includes training, validation and testing experiments. An experiment is
represented
by two RGB sequences :
- An observed sequence \(\mathbf{AB}\) with initial condition \(\mathbf{A}=\mathbf{X}_0\) and outcome
\(\mathbf{D} = \mathbf{X}_{t=1..T}\). This sequence is used during the abduction step, to identify
the counfounder variables.
- A counterfactual sequence \(\mathbf{CD}\) derived from \(\mathbf{AB}\). The initial conditions
\(\mathbf{A}\)
and \(\mathbf{C}\) are linked through a do-operator \(do(\mathbf{X}_0 = \mathbf{C})\), which
modifies the
initial condition through a visual intervention on the initial condition.
A do-operation consists in a visually observable change in the initial physical setup, such as object
displacement or removal.
Experiments are parameterized by a set of intrinsic physical parameters which are not observable
from a single initial image A, refered as confounders. The counterfactual task consists in inferring the
counterfactual
outcome \(\mathbf{D}\) given the observed trajectory \(\mathbf{AB}\) and the counterfactual initial state
\(\mathbf{C}\).
 Paper
Paper GitHub
GitHub Dataset
Dataset